By Rylan O'Connell, Ryan Speers | December 2, 2019
In our previous blog, we described some examples of where binary hashing can help solve problems and compared a number of algorithms for both basic block and graph aware hashing. Today we are releasing a tool, Hashashin, which combines some of these algorithms to allow security researchers to port Binary Ninja annotations from one binary to another.
Specifically, we developed this to assist researchers under DARPA’s SafeDocs program1 to apply annotations developed on instantiation of a parsing library to other instances of the library.
Our Approach
To implement this, we built Hashashin using some of the algorithms discussed in our previous blog. Specifically, this includes:
- Locality Sensitive Hash (LSH) for hashing the basic blocks
- Weisfeiler Lehman Isomorphism Test (WLI) for hashing with awareness of the graph structure
Importantly, we haven’t applied the LSH to the mnemonics of the assembly instructions within
the basic block, but instead we have taken advantage of Binary Ninja’s ability to lift the assembly to the
Medium Level Intermediate Language (MLIL), and then we run against this intermediate language (IL).
This allows us to take advantage of several features such as abstracting away “boilerplate” code (such as function
prologue/epilogs), and “lumping” similar assembly into the same MLIL operation.
This lumping makes our task of vectorizing each basic block significantly easier, as we only need to worry about a
fixed number of MediumLevelILOperations.
You may also notice that we chose WLI over Graph Edit Distance (GED) for our hashing algorithm for the graph. While GED may provide a better (analog) metric for function similarity, we found that WLI lent itself particularly well to our use case for binary hashing. Not only is GED slow under most conditions2, but we would also need to run this comparison between every pair of functions. WLI, on the other hand, allows us to run once and generate a fixed “hash” for that function which can be compared efficiently with other function hashes.
Those of you that are familiar with Quarkslab’s work may have noticed the similarity between our approach and the approach outlined in their recent blogpost3. Despite exploring a number of other techniques for binary hashing (see part 1 of this blog post for more details), we found that their approach was the best suited for use with an IL, and yielded impressive results with minimal modification.
How does the tool work?
Generate Signatures
The first step is to Generate Signatures. As input to this step, you need a binary that has been labeled. In our work, we typically take a library or binary and apply Tags within Binary Ninja to annotate the desired features. The tool runs over the resulting Binary Ninja database.
Within this stage, the following algorithm is followed:
- For each function:
- Label basic blocks
- Vectorize blocks
- Generate consistent hyperplanes
- Hash using LSH algorithm
- Hash labeled CFG
- Run Weisfeiler Lehman
- Associate metadata with function hash
- Label basic blocks
- Record hash → metadata mapping
Apply Signatures
Next, suppose that you have another binary which you believe contains similar code, such as a statically compiled library. At this point, we Apply Signatures. The tool runs over the target binary, and takes the generated signatures as input.
Within this stage, the following algorithm is followed:
- Load signature DB
- For each function:
- Label basic blocks
- Vectorize blocks
- Generate consistent hyperplanes
- Hash using LSH algorithm
- Hash labeled CFG
- Run Weisfeiler Lehman
- Lookup hash in signature DB
- Apply metadata to function
- Label basic blocks
Using the tool
We are very excited to release this tool as open source, and you can find it on GitHub at https://github.com/riverloopsec/hashashin. As described above, it allows a researcher to generate signatures, and then apply these signatures.
./src/generate_signatures.py <input_bndb> <signature_file>
For example:
# ./src/generate_signatures.py xpdf-linux-pdftotext-64_tagged.bndb xpdf-linux-64-pdftotext.sig
Loaded BNDB xpdf-linux-pdftotext-64_tagged.bndb into Binary Ninja.
984 functions in binary have been hashed.
984 signatures have been created based on the present tags.
Signature file written to xpdf-linux-64-pdftotext.sig.
Once this is completed, you can use this signature file as many times as desired to apply it to other binaries:
./src/apply_signatures.py <input_binary> <signature_file>
For example:
# ./src/apply_signatures.py tests/xpdf-4.01.01/linux/bin64/pdfinfo xpdf-linux-64-pdftotext.sig
Loaded binary tests/xpdf-4.01.01/linux/bin64/pdfinfo into Binary Ninja.
900 functions in binary have been hashed.
Signature file xpdf-linux-64-pdftotext.sig loaded into memory.
Writing output Binary Ninja database at /processor/tests/xpdf-4.01.01/linux/bin64/pdfinfo.bndb
Results
To evaluate the success of this method, we manually labeled a PDF parsing library, xpdf, in the context
of the xpdf pdftotext program (version 4.01.01).
Specifically, different basic blocks were labeled depending on what internal PDF object they were handling or
what type of parsing logic they were applying.
We then collected a number of other binaries which have varying levels of relations to the xpdf library. We did not test with these during design and implementation of the program to keep the evaluation free of over-fitting to a specific sample set.
The binaries used are described here:
| Binary Name | Version | Architecture | Debug Symbols4 | Percent of Tags Ported |
|---|---|---|---|---|
| pdfimages | 4.01.01 | x86-64 | Y | 98.5% |
| pdfinfo | 4.01.01 | x86-64 | Y | 98.3% |
| pdftotext | 4.01.01 | x86 | Y | 30.5% |
| pdfimages | 4.01.01 | x86 | Y | 30.5% |
| pdftotext | 4.02 | x86-64 | Y | 94.8% |
| pdfimages | 4.02 | x86-64 | Y | 90.5% |
For each target binary which we attempted to apply labeling to, we used the benchmarking.py script which we have
also released in the GitHub repository to calculate how many tags were ported, as well as how many functions were matched.
This allows us to track the efficacy of the tool against different problem sets.
These results show that porting within similar versions on the same architecture is highly effective, whereas porting across architectures leads to significant reductions in efficacy - but still some basic blocks can be aligned.
The types of tags ported include tags for where PDF dict, name, trailer, comment, bool, literal, stream, array, real, xref, string, hex, header, and number, and indirect objects/references are parsed within the PDF parser’s logic.
Details of Steps
For those interested, we will share the internals of the steps here, although of course you can also follow along in the open-source tool.
In these descriptions, we utilize Binary Ninja API names to be specific about the implementation we have built.
Vectorizing Blocks
In this step, we construct a “bag of words” for each MediumLevelILOperation.
This bag is treated as order agnostic, as this is done by collecting operations within a basic block.
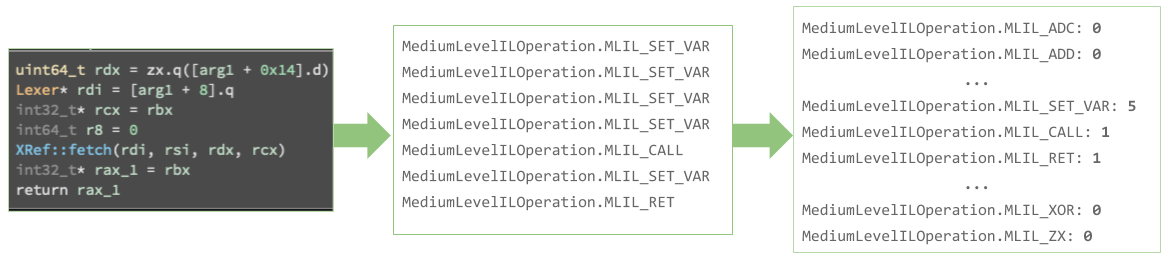
The benefit to this approach is that the exact instructions in a basic block can differ just so long as overall function is the same (since similar instructions coalesce into the same MediumLevelILOperation).
This property, combined with our “bag of words” approach, means that complex basic blocks which perform similar computation will produce vectors that “point” in similar directions (as they will have similar ratios of MediumLevelILOperations).
Generating Hyperplanes
Many implementations of LSH randomly generate hyperplanes at each runtime, however this is not an option for us as we seek to generate reusable signatures. To decide how to generate these, we consider a few questions to determine the optimal distribution of hyperplanes:
- Should they divide the space evenly?
- Should they account for the natural bias of our input vectors in certain “directions”?
- How many hyperplanes is too many? How about too few?
- The more hyperplanes, the more “buckets” there are, and the more granular the hashes.
- This quickly becomes a problem of balancing our hash’s fuzziness with its accuracy.
For our use case, the only real constraints are that:
- Hyperplanes must be deterministic
- Hyperplanes must be the same dimension as our vectors (i.e., there are currently 131
MediumLevelILOperations, meaning that our hyperplanes will have to have 131 dimensions as well)
Ultimately, we decided on an arbitrary algorithm to generate hyperplanes that seems to work “well enough” for our purposes. In the future, we will need to invest more time into exploring each of the above questions, as there may be room for improvement. However, many implementations of this algorithm generate new hyperplanes randomly every time, so it seems likely that the exact distribution of these hyperplanes won’t have a significant impact on our overall performance.
Graph Aware Hashing
After we have hashed each basic block using the locality sensitive hashing algorithm described in our previous post, we can treat each basic block’s hash as a label in the CFG. Because WLI operates on graphs with labeled nodes, it then becomes trivial to run WLI and generate an overall hash for the function.
As you may recall from our previous blog post, WLI is not a “true” test of isomorphism - that is, it merely acts as a heuristic to check if two graphs are similar through a series of rounds of neighborhood visitation and relabeling. By increasing the number of rounds we can improve the accuracy of this heuristic. However, we found that increasing the number of rounds of tests run by our algorithm slowed our program significantly with a minimal gain in accuracy. For this reason, we elected to default to a single round of WLI for our tool.
Future Work
While our tool functions perfectly fine for our use case, there is room for improvement - especially with regards to efficiency.
As some of you may have picked up on, our algorithm involves several steps (such as hashing every function in a binary,
or every basic block in a function), which could be trivially parallelized.
Unfortunately, Python’s multiprocessing library relies heavily on pickle, which is unable to handle ctypes used
under the hood by Binary Ninja.
As such, we need to restructure code to reap the benefits of our highly parallelizable algorithm.
However, Python 3.8 makes several changes to the multiprocessing library which we believe will allow us to perform
much of our expensive computation in parallel.
Additionally, there are many areas where we choose to err on the side of readability over raw performance. By opting to use Python features such lambdas and precomputing our hyperplanes, we would likely attain a noticeable decrease in run times. While these optimizations were not implemented for our original use case, we encourage interested readers to contribute to the tool.
As we port tags today between databases, other logical data types to port are types, names, or comments. Given the difficult work of aligning similar basic blocks has been implemented, we expect that one could add these features with relatively minimal effort. Fields that could be moved over include:
- Types
binaryninja.function.Variable.typebinaryninja.types.FunctionParameter.type
- Names
binaryninja.types.FunctionParameter.namebinaryninja.function.Variable.namebinaryninja.function.Function.name
- Comments
binaryninja.binaryview.address_commentsbinaryninja.function.comments
Similarly, library identification could be implemented where unique identifiers in the library are used as part of the signature, and the surrounding area is then isolated, hashed, and compared. This algorithm is similar to what is used in KARTA5.
A more difficult problem is making this work cross-platform. Although ILs abstract calling convention, platform specific registers, instructions, and similar, there are still a number of practical challenges involved in comparing binaries compiled for different platforms/architectures. We believe that a key reason for these issues relates to the compilers used. On different platforms, the same code could be compiled with GCC, Clang, MSVC, MinGW, or more – and these all handle optimizations slightly differently. As a result, we see that the CFG will differ between binaries compiled from the same codebase, which in turn will require more sophisticated graph comparison.
Finally, you will note that this is not a “bindiff” type tool in its current implementation. Although binary diffing has a number of similarities, we have adjusted algorithm selection and thresholds in the current tool to focus on solving the problem of porting annotations which we describe above. Additional work can be done to leverage this as a traditional “bindiff” tool and we hope to collaborate with others working on similar tools.
Conclusion
While the problem of function recognition has been tackled numerous times before, many of the established tools rely on byte level hashing with relatively brittle heuristics, or incur significant computation due to the amount of data required for ML based techniques or similar.6 We believe that a transition towards the use of intermediate languages and the use of more flexible “fuzzy” hashing algorithms will pave the way to more robust tooling which will be less prone to false positives/negatives.
We hope that this tool is useful to you in your research or work. We welcome feedback, issues (see our GitHub issue tracker, and contributions of additional features or improvements.
While we are under no illusion about our tool replacing the incumbent technologies today, we hope that it will serve as a persuasive proof of concept for others, and that we can develop this work into even more mature tooling with the help of the wider program analysis community.
River Loop Security works heavily in applying program analysis techniques to solve real-world problems in cybersecurity, from research projects such as DARPA’s SafeDocs program to commercial penetration testing engagements where we audit source code or binaries to find vulnerabilities.
We encourage you to contact us if you have any questions or comments based on this post or have questions about applying binary analysis to solve your cybersecurity challenges.
This material is based upon work supported by the Defense Advanced Research Projects Agency (DARPA) under Contract No. HR001119C0074. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the Defense Advanced Research Projects Agency (DARPA).
Distribution Statement A: Approved for Public Release.
-
Bratus, S. Safe Documents. Retrieved from https://www.darpa.mil/program/safe-documents. ↩︎
-
Josh Watson (a veritable fount of Binary Ninja wisdom) has been developing a bindiffing plugin for Binary Ninja, where he is attempting to leverage certain properties of CFGs to improve the efficiency of GED ↩︎
-
Mengin, Elie (2019, September 09). Weisfeiler-Lehman Graph Kernel for Binary Function Analysis. Retrieved from https://blog.quarkslab.com/weisfeiler-lehman-graph-kernel-for-binary-function-analysis.html ↩︎
-
Although we show if debug symbols were present in the above table, we do not leverage debugging symbols as part of the analysis methodology. ↩︎
-
Itkin, E. (2019, March 21). Karta – Matching Open Sources in Binaries. Retrieved from https://research.checkpoint.com/2019/karta-matching-open-sources-in-binaries/ ↩︎
-
This sentence was updated 2019.12.12 to reflect the state-of-the-art more accurately thanks to feedback from Halvar Flake. The original reference to brittle heuristics was based on techniques such as using cryptographic hashes with the inputs computed many different ways in some tools. ↩︎