By Douglas Gastonguay-Goddard | August 19, 2020
The National Imagery Transmission Format (NITF) was brought to our attention under the DARPA SafeDocs program. In this program, we are using binary instrumentation and static analysis to understand parsers’ de facto file format specifications. The NITF format is a container format for other image files. It details a large amount of metadata, such as classification info for each file and sub-section. A single NITF file can contain, for example, multiple images, text annotations, and graphics.
This blog post shares our analysis of the format, and updates to the format that we have proposed to the NITF Technical Board. We focus on features or specification language that we believe are likely to lead to implementation errors and vulnerabilities.
We thank the NITF Technical Board for their collaboration in discussing these suggestions and their commitment to improving the specification to promote security.
During our research into a parser for this file format, we found a global buffer overflow which leads to a write-what-where. This flaw has been assigned CVE-2020-13995 and will be disclosed in a separate blog post.
The NITF format acts as a container format for other image files and contains a large amount of metadata. Additionally, the format is also extensible with Tagged Record Extensions (TRE). These TREs do not appear to be well documented publicly. The format is largely ASCII-based, for example, size fields are specified in ASCII which a parser then converts to integers (e.g. atoi()). The specification is published as MIL-STD-2500C and related documents.
There is also the NATO Secondary Imagery Format (NSIF) which appears to be, for the most part, identical to NITF with the exception of the magic bytes and version.
Suggested NITF Updates
In April 2020 we reviewed the NITF specification version 2.1. In doing so we identified 7 areas that may lead to differing interpretations and implementations in parsers. While we reviewed this specification manually, our overall goal in the Safedocs program is to extract each parser’s interpretation of the specification programmatically.
Issue 1
The NITF 2.1 format contains multiple character set specifications. The Extended Character Set (ECS) covers the bytes 0x20 - 0x7E, 0xA0 to 0xFF, and 0x0A, 0x0C, and 0x0D. However, there is a suggested restriction for ECS. As an interim measure, because of inconsistencies between standards, it is strongly advised that character codes ranging from 0xA0 to 0xFF should never be used. It is our hypothesis that this ambiguous language will create differences between parsers. Should they reject the characters outside of the suggestion? Warn? Accept them to meet the specification?
Recommended Revisions
The suggestion creates ambiguity. It should be removed and replaced by a concrete action. Specify what behavior a parser should take when it encounters bytes 0xA0-0xFF in ECS fields. For testing and certification purposes, we suggest creating a test file that can be used to validate this behavior. Alternatively, update the ECS field to remove these bytes.
Issue 2
There are multiple nested size fields. The first example is the FL (File Length) and HL (Header Length) fields. FL is a 12 character integer whereas HL is a 6 character integer. Interesting areas to explore with these nested size fields include creating situations where HL exceeds FL or where the actual file size is smaller than FL.
The streaming (trailing) file header has been deprecated. This analysis is left in as an example of nested size fields. Additionally, the Data Extension Segment Streaming File Header structure is used to append a file header to the end of a NITF file when the size of fields were not known at the time of writing the initial (start-of-file) file header. In other structures the DESSHL field is immediately followed by a DATA field for which it describes the length. The assumption here is the DESSHL refers to the size of the SFH_* fields that follow it. The issue is that the field SFH_L1 also describes the length of a field contained herein, SFH_DR. The fact that DESSHL is 4 bytes long while SFH_L1 is 7 bytes long could lead to some interesting behavior in parsers.
Data Extension Segment Streaming File Header structure from MIL-STD-2500C TABLE A-8(B).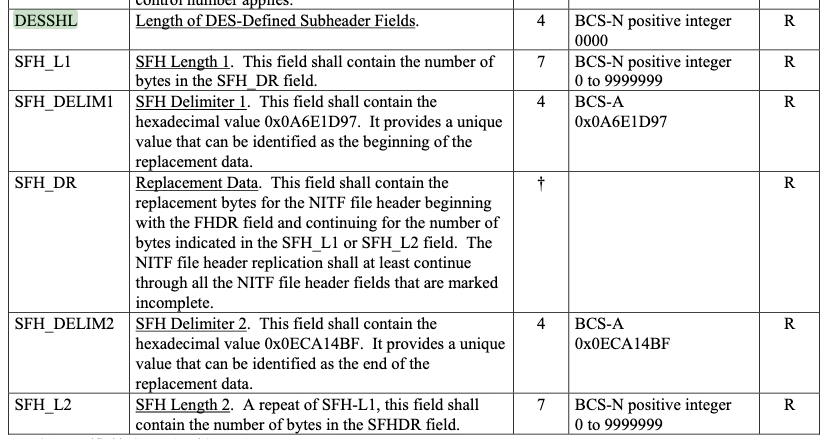
Recommended Revisions
Size fields are often an opportunity for formats to lie about reality. This is especially true when there are other source of truth (e.g. a file size, a calculable size) that a parser may use to consume bytes. These situations create differentials where a buffer may be allocated from one source, but read into from another. This could lead to memory corruption.
It is our recommendation to explicitly define the relationship between nested size fields. For situations that should not exist (e.g. HL > FL), assert that relationship and indicate that parsers must enforce it, and the action they should take when it is encountered.
Issue 3
The File Date and Time field (FDT) specifies a format CCYYMMDDhmmss, intended to be a numeric date. The character set used for this field is BCS-N which allows for the characters ‘0’ - ‘9’, ‘+’, ‘-’, ‘.’, and ‘/’. Unknown values are replaced with the ‘-’ character. The question that arises is how parsers handle the BCS-N valid characters that are not used in the date (‘+’, ‘.’ and ‘/’). Will they abort on any character outside the defined set or will they ignore any (still valid) BCS-N character outside of the date set? Additionally, they may allow any characters (non-BCS-N) if the field is ignored.
Recommended Revisions
Create a specific character set for the FDT field. Indicate how a parser should behave when an invalid FDT character is encountered. Should the full BCS-N character set be accepted and any non-numeric be treated as a ‘-’? Or should the parser reject any FDT field containing characters outside of ‘0’ - ‘9’ and ‘-’? Clearly defining these relationships will prevent divergence between parser implementations.
Issue 4
The NITF format contains a structure in most segments that specifies information about the classification of that segment (file, image, graphic, etc.). The first field in this structure FSCLAS is a 1 byte field that specifies the classification using the values T (=Top Secret), S (=Secret), C (=Confidential), R (=Restricted), U (=Unclassified). This field is ECS-A (0x20 - 0x7E and 0xA0 - 0xFF) despite only using BCS-A (0x20 - 0x7E) characters. This is a loose restriction on a field that can only be one of 5 values.
Recommended Revisions
Restrict FSCLAS to be BCS-A. Specify how an application should behave when values outside of the valid set (T, S, C, R, U) are encountered. Another suggestion would be to break out the classification structure, as it is repeated among many segments. Create a single definition for the structure and embed that object in each segment that it is used. This would encourage a single source of the parsing logic for this repeated structure.
Issue 5
The file header contains repeated length fields specifying the length of image segments and their headers. LISHn is the length of image sub-header N. It is a 6 byte BCS-N positive integer with a minimum value of 000439. Following that, is LIn which is the length of image segment N. This is a BCS-N positive integer of length 10 with a minimum value of 0000000001.
File Format Diagram from MIL-STD-2500C FIGURE 5
This figure creates some confusion with the above definitions. Image segment is used as a term to encompass the header and the data field. The size specifications, however, hint that the header is not nested within the segment size (LIn).
In practice, parsers treat the segment size as the Image Data Field size, as is hinted by the minimum sizes but contradicts the above figure.
Recommended Revisions
Rename the segment size fields (LIn, LSn, LTn, etc.) to data size fields. This will allow “segment” to refer to the header and data, and properly identify that those size fields are for the data and not the entire segment.
Issue 6
The Block N Band M (BMRnBNDm) field contains N block mask records (4 bytes) for each M bands. These records repeat for a number of rows (NBPR) by a number of columns (NBPC), i.e. NBPR * NBPC. If the image mode (IMODE) is S, there is a set of repetitions (M) for max(NBANDS, XBANDS) (will be referred to here simply as BAND_COUNT). That is, there will be BAND_COUNT * NBPC * NBPR block mask records. There are two issues with how this is specified.
BMRnBNDm value range definition from MIL-STD-2500C TABLE A-3(A)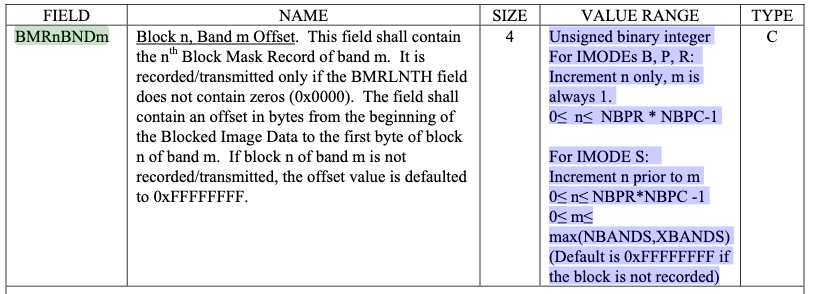
In non-S modes, m is always 1. This is an odd choice as in all other cases values are zero indexed. This does not affect the parsing of the format though. There is, however, an off by one error in the acceptable range of m. It should have a maximum value of max(NBANDS, XBANDS) - 1.
Recommended Revisions
Zero index the m when in modes B, P, and R. For S mode, fix the off-by-one error by changing the definition of m to 0 <= m < max(NBANDS, XBANDS). That is, m should not be equal to max(NBANDS, XBANDS).
Issue 7
As well, the BMRLNTH field (2 byte unsigned big endian integer) is used to indicate the presence of the BMRnBNDm repetition. When BMRnBNDm is present, BMRLNTH contains the value 4 (0x0004) to indicate the size of block mask record entries. When not present it contains zero (0x0000). This is a future proofing method in case the size of the block mask record changes. The question is how parsers handle this if a non-zero, non-four value is provided. Will they adjust the size? Will any non-zero size be treated as 4? Will any non-four be treated as a 0? Will it affect how the parser advances but not the size of the buffer allocated or vice versa? There are many potential errors that could arise in how this interaction is implemented.
Recommended Revisions
Specify parser behavior when BMRLNTH contains a non-zero, non-four value. Create a test file for parser certification to validate how this situation would be handled.
Conclusion
Specifying file formats in natural language leaves a lot of details open to interpretation by developers. Combining these ambiguities and human fallibility with memory-unsafe languages leads to dangerous flaws in the software we rely on. As researchers, our job beyond discovering flaws is to create systems for eliminating them.
River Loop Security works daily in applying vulnerability analysis skills and techniques to solve real-world problems in cybersecurity, from research projects such as DARPA’s SafeDocs program to commercial penetration testing engagements where we audit source code or binaries to find vulnerabilities.
We encourage you to contact us about how we can help solve your cybersecurity challenges, including auditing file formats, specifications, or parsers!
This blog grew out research into how to find unsafe features in file formats as part of Dr. Sergey Bratus’ DARPA Safe Documents (SafeDocs) program.
Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the Defense Advanced Research Projects Agency (DARPA).